
About me
I am currently a last year Ph.D. candidate at Tsinghua University, supervised by Prof. Xiu Li. I was fortunate to be a visiting student at MMLAB@NTU, where I worked with Prof. Ziwei Liu on the intersection of MLLM and human motion. Earlier in my Ph.D. journey, I had the opportunity to explore digital human modeling under the kind guidance of Prof. Yebin Liu. Before beginning my Ph.D., I obtained my master’s degree from Northeastern University, where I conducted research on vision-language models under the supervision of Prof. Lu Meng. My research interests lie in human-centered vision, including modeling human motion and human-centric interactions for avatars, generative models, MLLMs and embodied intelligence.
🆕News
[Please visit my google scholar profile for the full publication list.]
✨Selected Publications
 | Lodge++: High-quality and Long Dance Generation with Vivid Choreography Patterns Ronghui Li, Hongwen Zhang, Yachao Zhang, Yuxiang Zhang, Youliang Zhang, Jie Guo, Yan Zhang, Xiu Li, Yebin Liu. IEEE Transactions on Pattern Analysis and Machine Intelligence. (Accepted) [Project][Paper][Code] |
 | Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives Ronghui Li, Yuxiang Zhang, Yachao Zhang, Yachao Zhang, Hongwen Zhang, Jie Guo, Yan Zhang, Yebin Liu, Xiu Li. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) [Project][Paper][Code] |
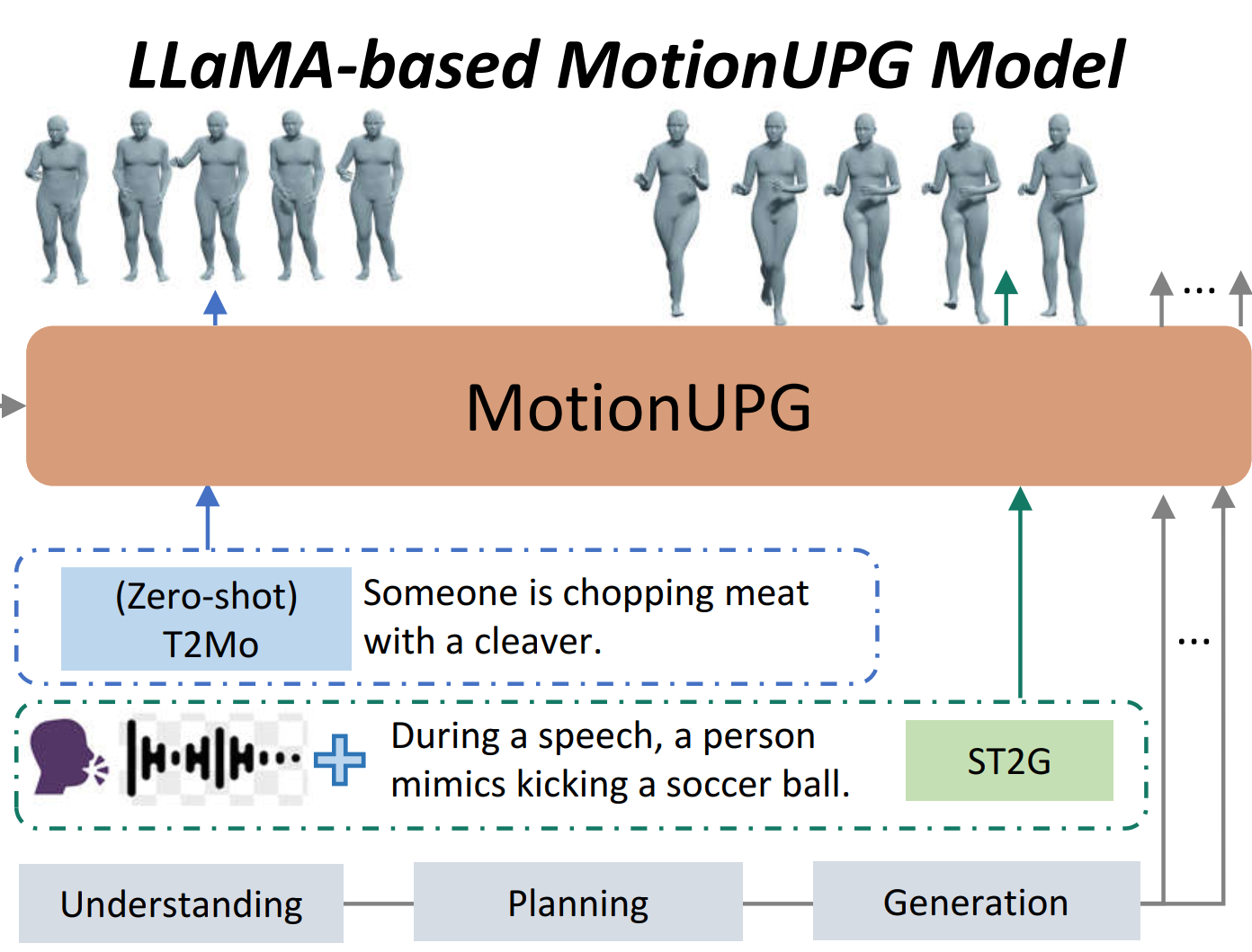 | A Motion is Worth a Hybrid Sentence: Taming Language Model for Unified Motion Generation by Fine-grained Planning Ronghui Li, Lingxiao Han, Shi Shu, Yueyao Liu, Yukang Lin, Yue Ma, Jie Guo, Ziwei Liu, Xiu Li. ACM International Conference on Multimedia. (ACM MM 2025) [Project page] |
 | FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation Ronghui Li, Junfan Zhao, Yachao Zhang, Mingyang Su, Zeping Ren, Han Zhang, Yansong Tang, Xiu Li. IEEE/CVF Conference on International Conference on Computer Vision (ICCV 2023) [Project][Paper][Code] |
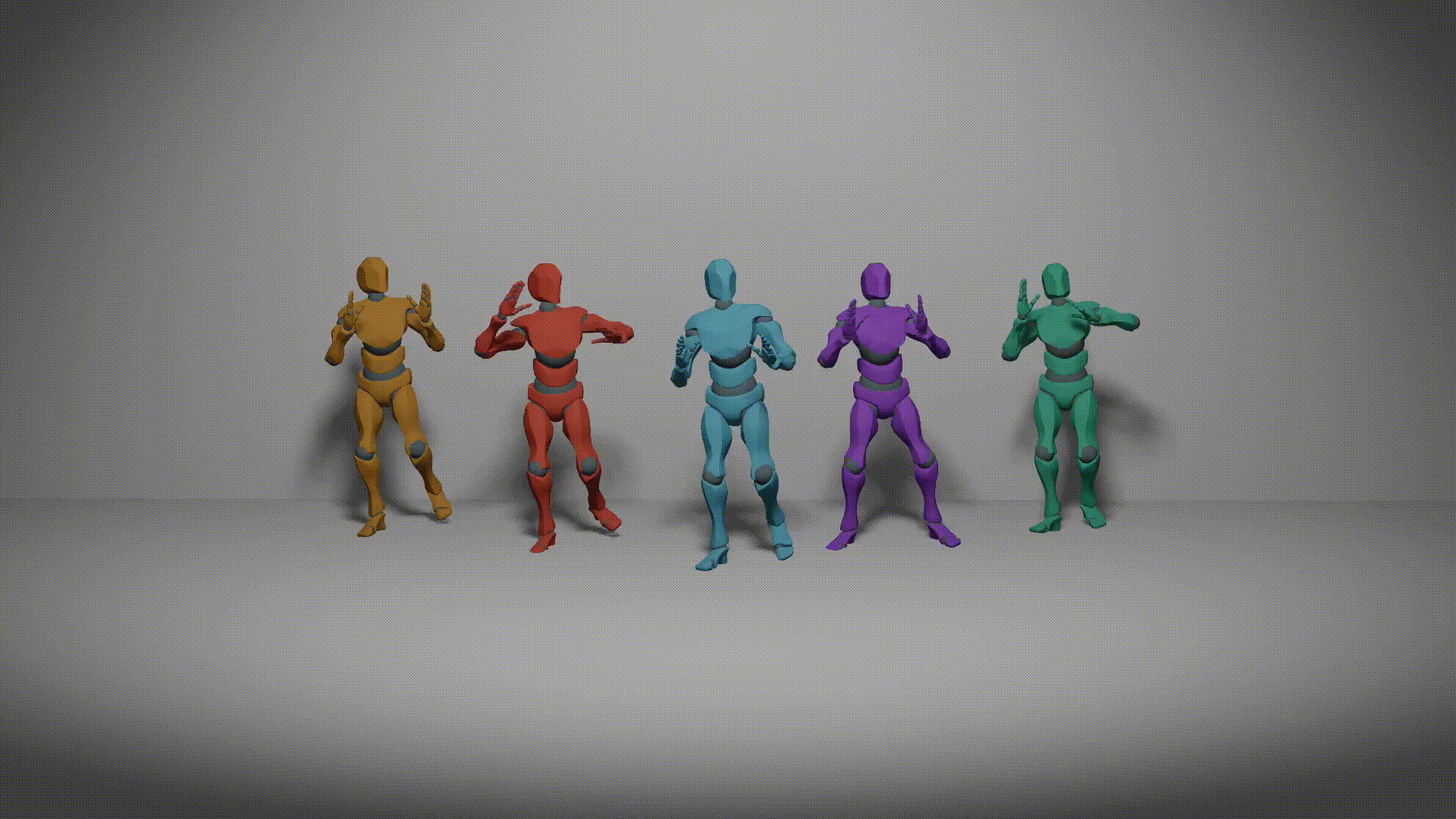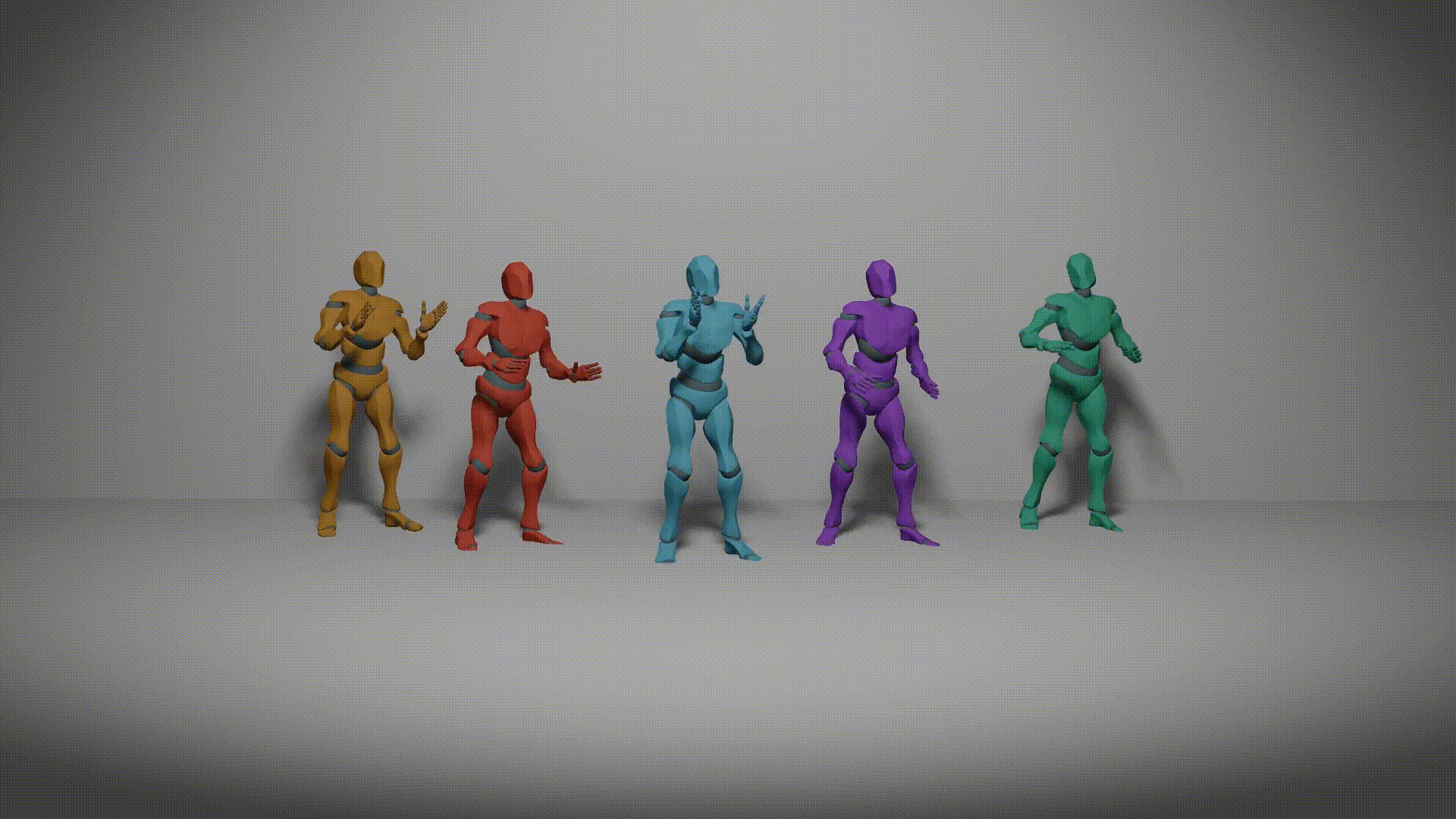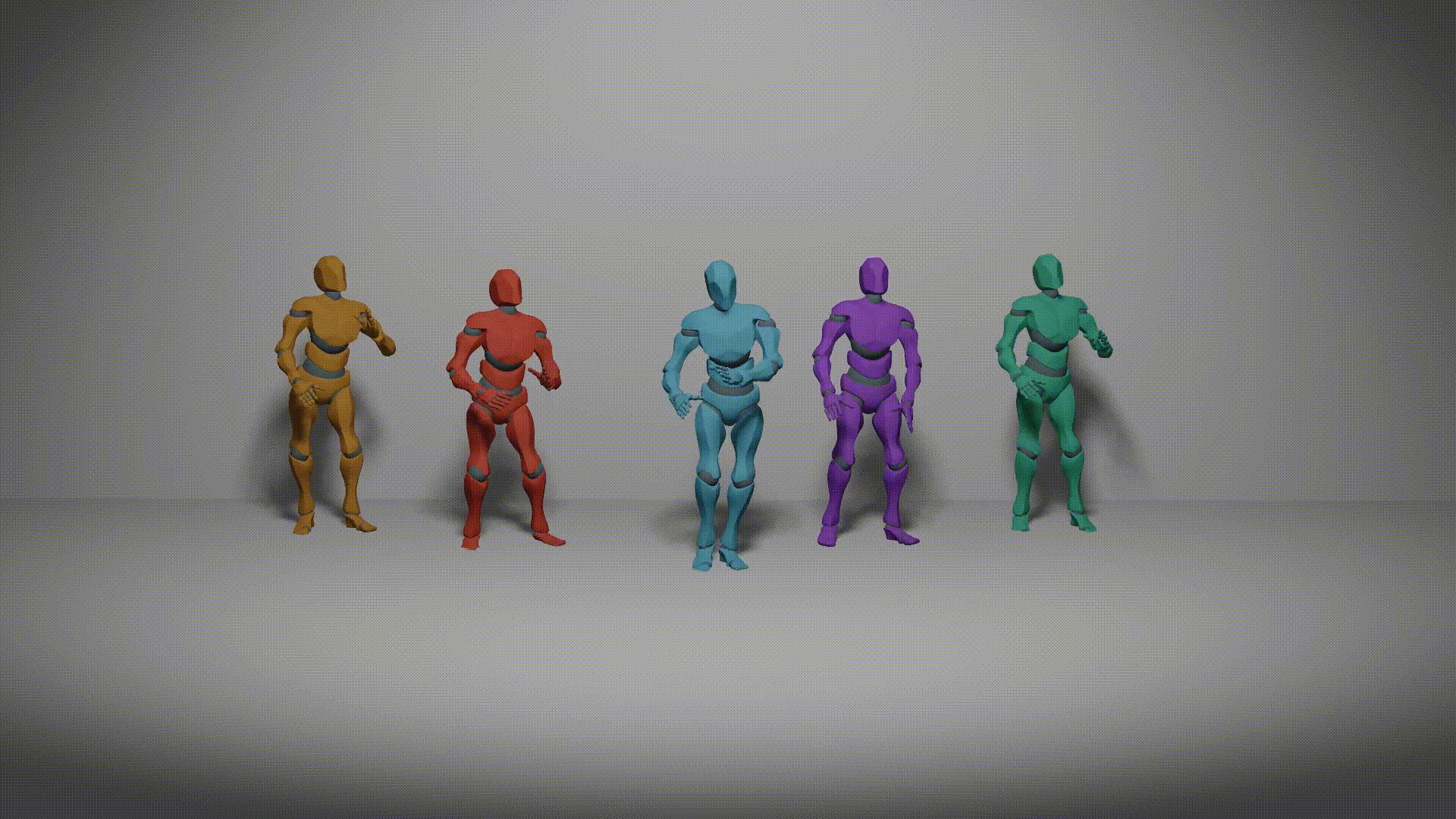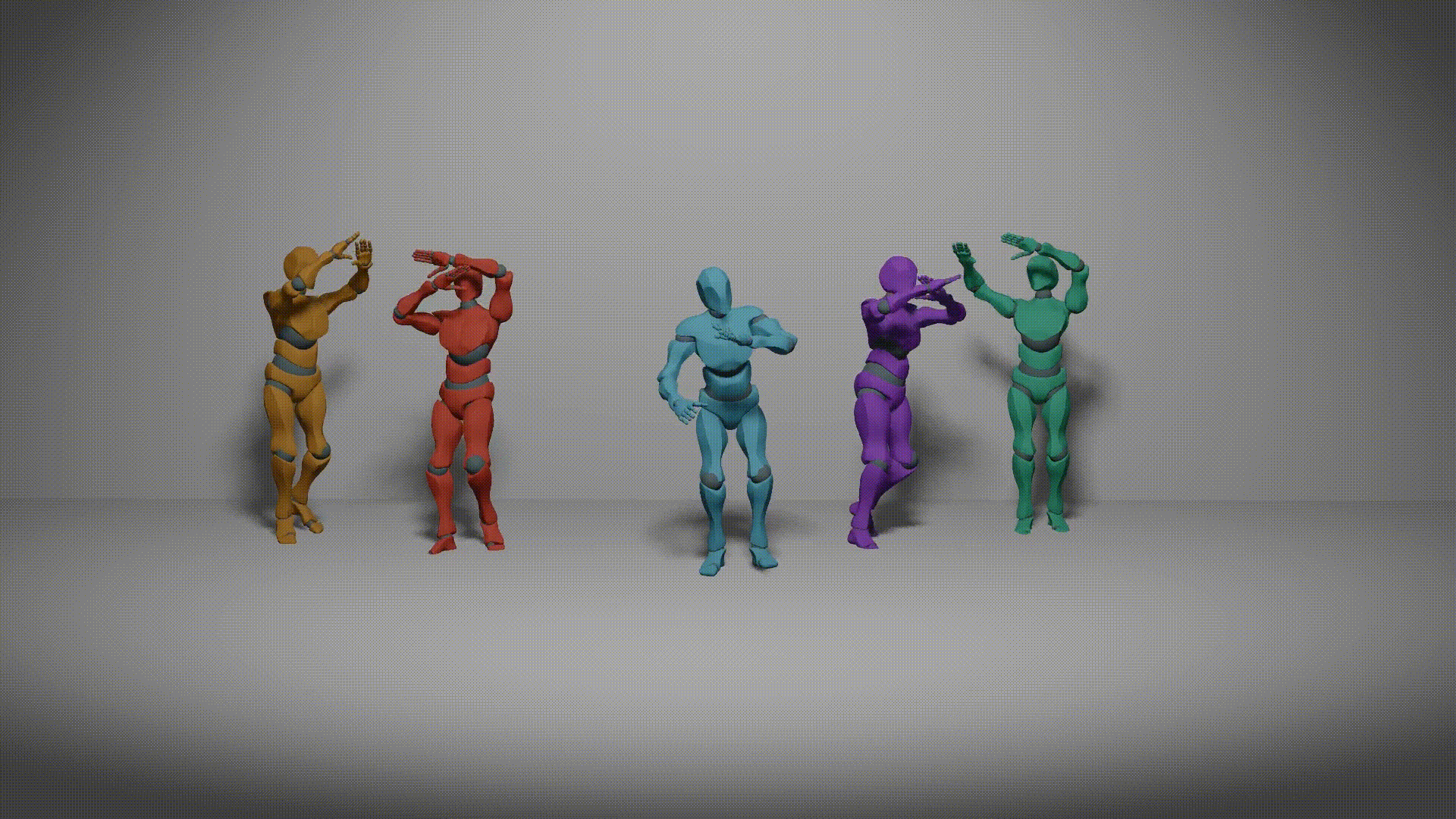 | Harmonious Group Choreography with Trajectory-Controllable Diffusion Yuqin Dai, Wanlu Zhu, Ronghui Li, Zeping Ren, Xiangzheng Zhou, Xiu Li, Jun Li1, Jian Yang. Association for the Advance of Artificial Intelligence (AAAI 2025) [Project][Paper][Code] |
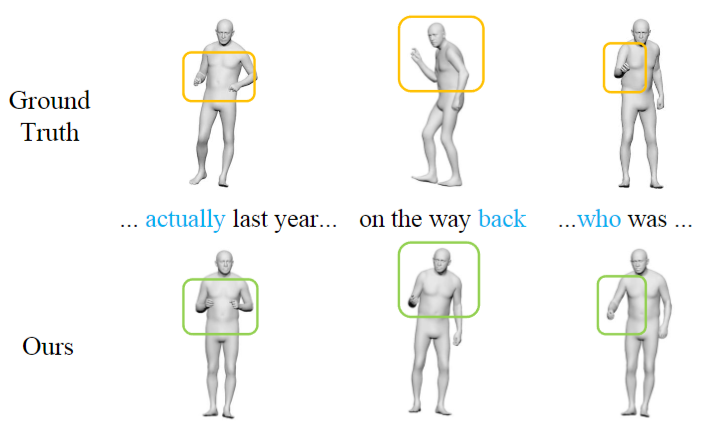 | MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models Zunnan Xu, Yukang Lin, Haonan Han, Sicheng Yang, Ronghui Li, Yachao Zhang, Xiu Li. Annual Conference on Neural Information Processing Systems (NeurIPS 2024) [Project][Paper][Code] |
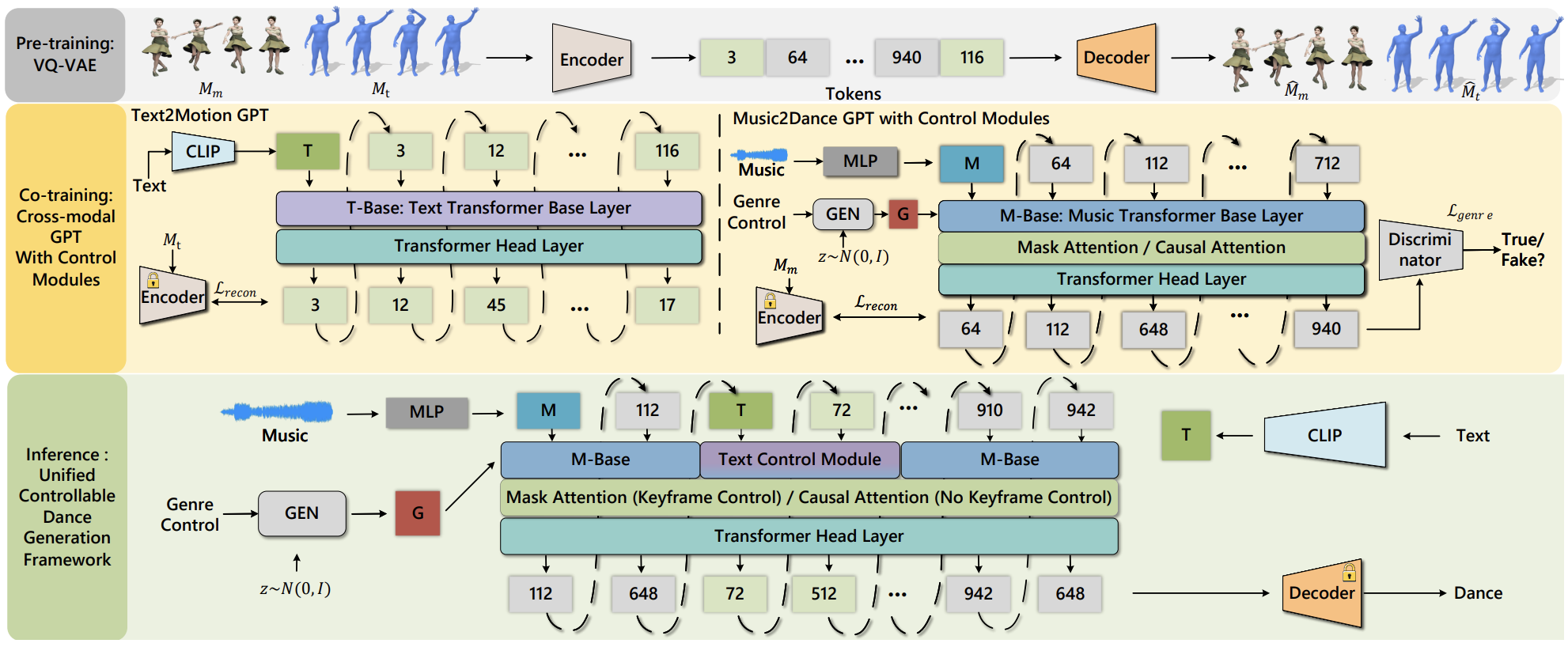 | Exploring Multi-Modal Control in Music-Driven Dance Generation Ronghui Li, Yuqin Dai, Yachao Zhang, Jun Li, Jian Yang, Jie Guo, Xiu Li. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024) [Paper] |
 | A Plug-and-Play Physical Motion Restoration Approach for In-the-Wild High-Difficulty Motions Youliang Zhang★, Ronghui Li★, Yachao Zhang, Liang Pan, Jingbo Wang, Yebin Liu, Xiu Li. IEEE/CVF Conference on International Conference on Computer Vision (ICCV 2025) [Project][Paper] |
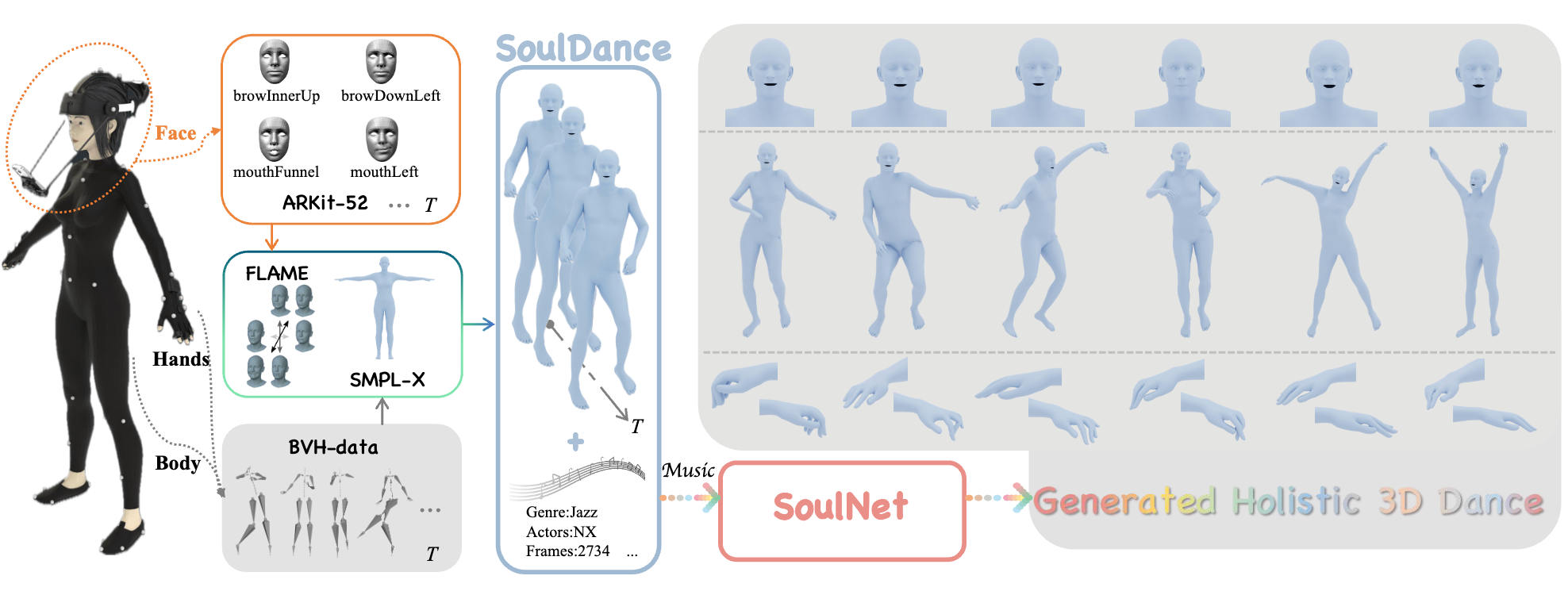 | SoulDance: Music-Aligned Holistic 3D Dance Generation. Xiaojie Li, Ronghui Li, Shukai Fang, Shuzhao Xie, Xiaoyang Guo, Jiaqing Zhou, Junkun Peng, Zhi Wang. IEEE/CVF Conference on International Conference on Computer Vision (ICCV 2025) [Project][Paper][Code] |
 | TCDiff++: An End-to-end Trajectory-Controllable Diffusion Model for Harmonious Music-Driven Group Choreography. Yuqin Dai, Wanlu Zhu, Ronghui Li, Xiu Li, Zhenyu Zhang, Jun Li, Jian Yang. International Journal of Computer Vision (IJCV) [Project][Paper][Code] |
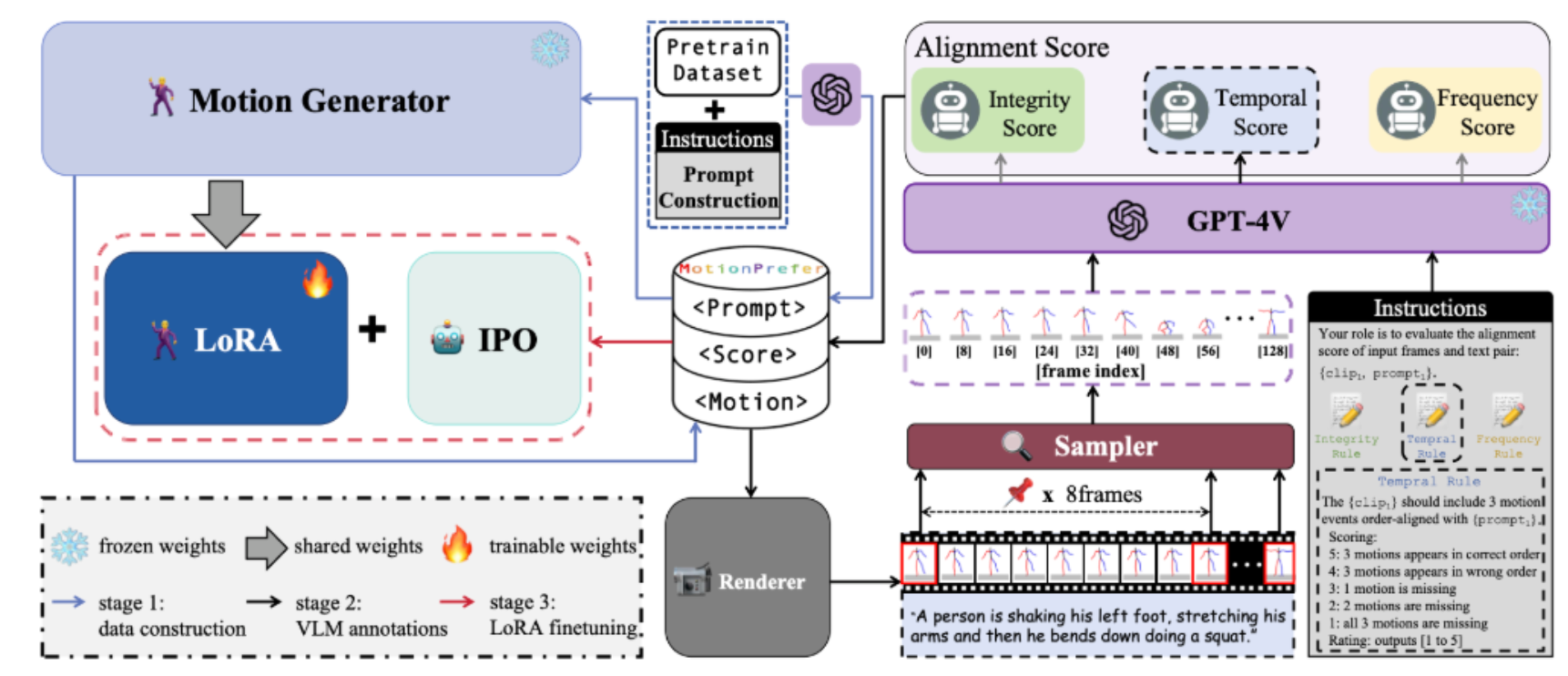 | AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward. Haonan Han, Xiangzuo Wu, Huan Liao, Zunnan Xu, Zhongyuan Hu, </strong>Ronghui Li</strong>, Yachao Zhang, Xiu Li. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025) [Project][Paper][Code] |
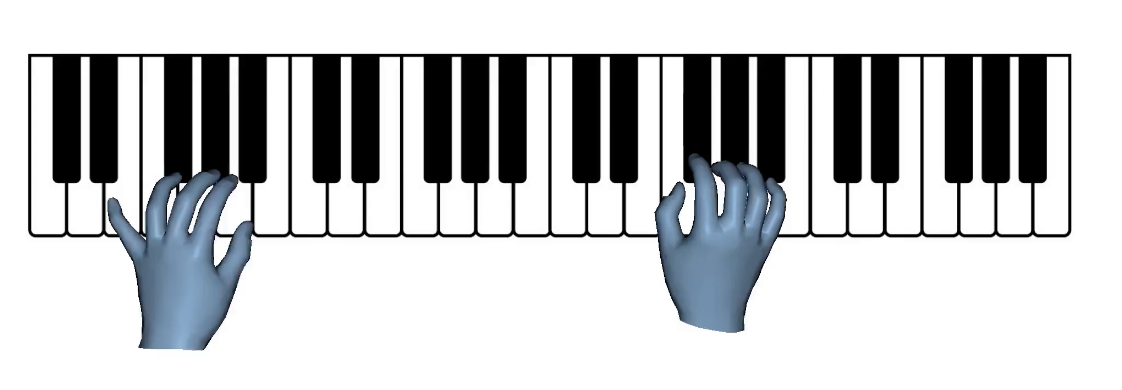 | Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis. Zihao Liu, Mingwen Ou, Zunnan Xu, Jiaqi Huang, Haonan Han, Ronghui Li, Xiu Li. ACM International Conference on Multimedia (ACM MM 2025) [Project][Paper][Code] |
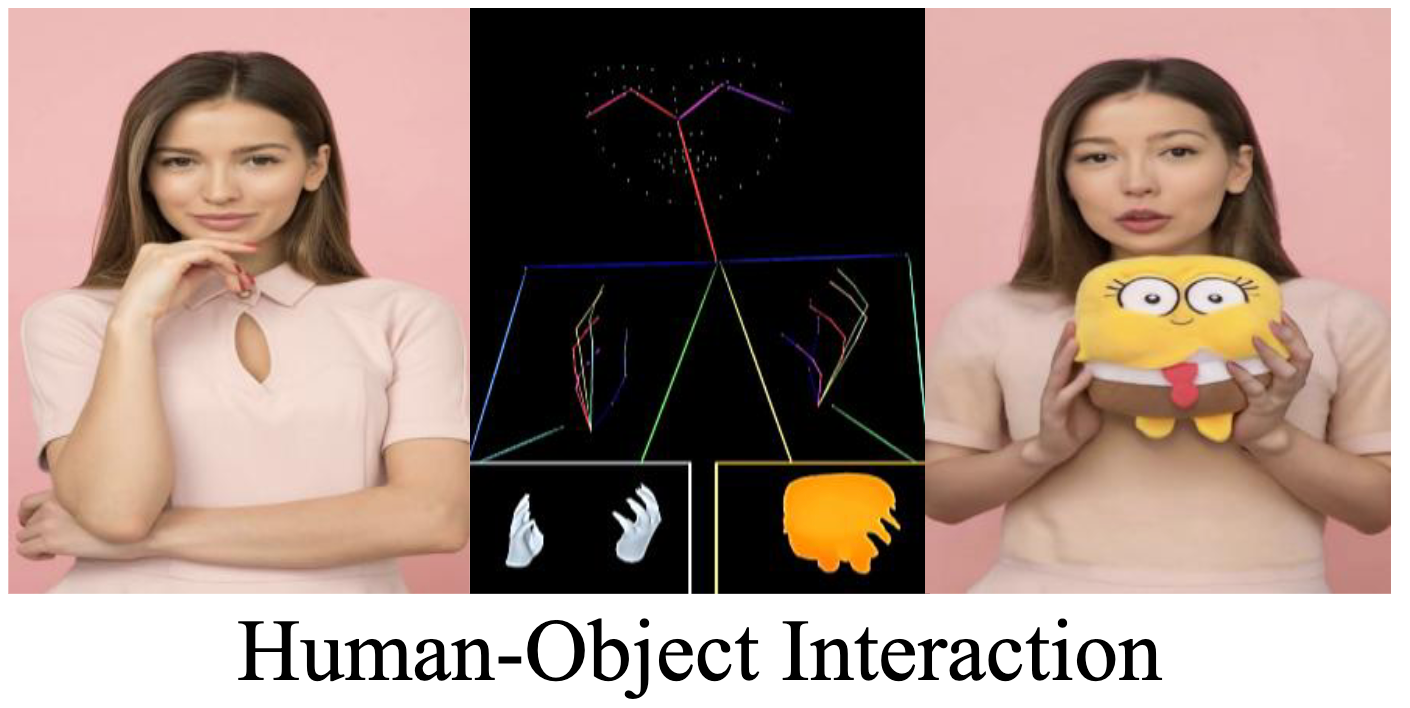 | Interanimate: Taming region-aware diffusion model for realistic human interaction animation. Yukang Lin, Yan Hong, Zunnan Xu, Xindi Li, Chao Xu, Chuanbiao Song, Ronghui Li, Haoxing Chen, Jun Lan, Huijia Zhu, Weiqiang Wang, Jianfu Zhang, Xiu Li. ACM International Conference on Multimedia (ACM MM 2025) [Project][Paper] |
| | Text2Avatar: Text to 3D Human Avatar Generation with Codebook-Driven Body Controllable Attribute Chaoqun Gong, Yuqin Dai, Ronghui Li, Achun Bao, Jun Li, Jian Yang, Yachao Zhang, Xiu Li. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024) [Paper] |
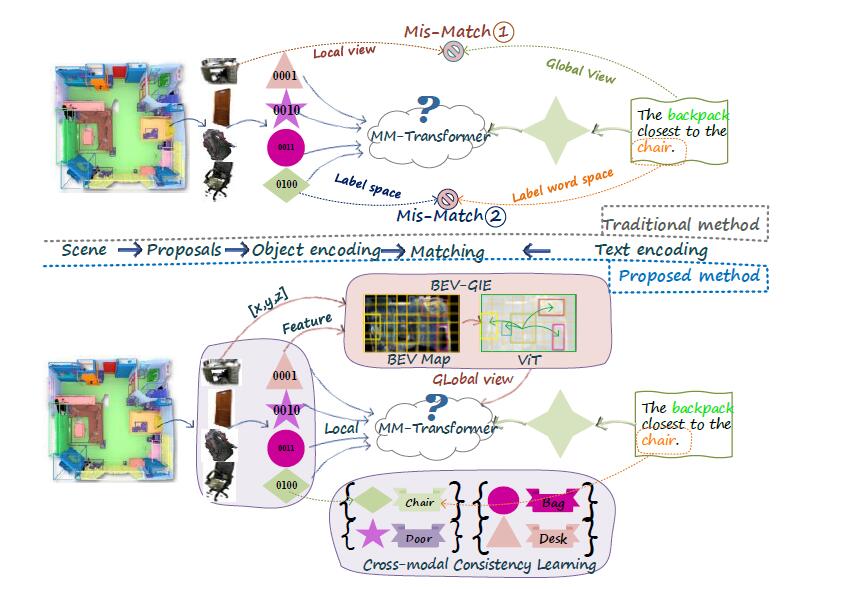 | Cross-Modal Match for Language Conditioned 3D Object Grounding Yachao Zhang, Runze Hu, Ronghui Li, Yanyun Qu, Yuan Xie, Xiu Li. Association for the Advance of Artificial Intelligence (AAAI 2024) [Paper] |
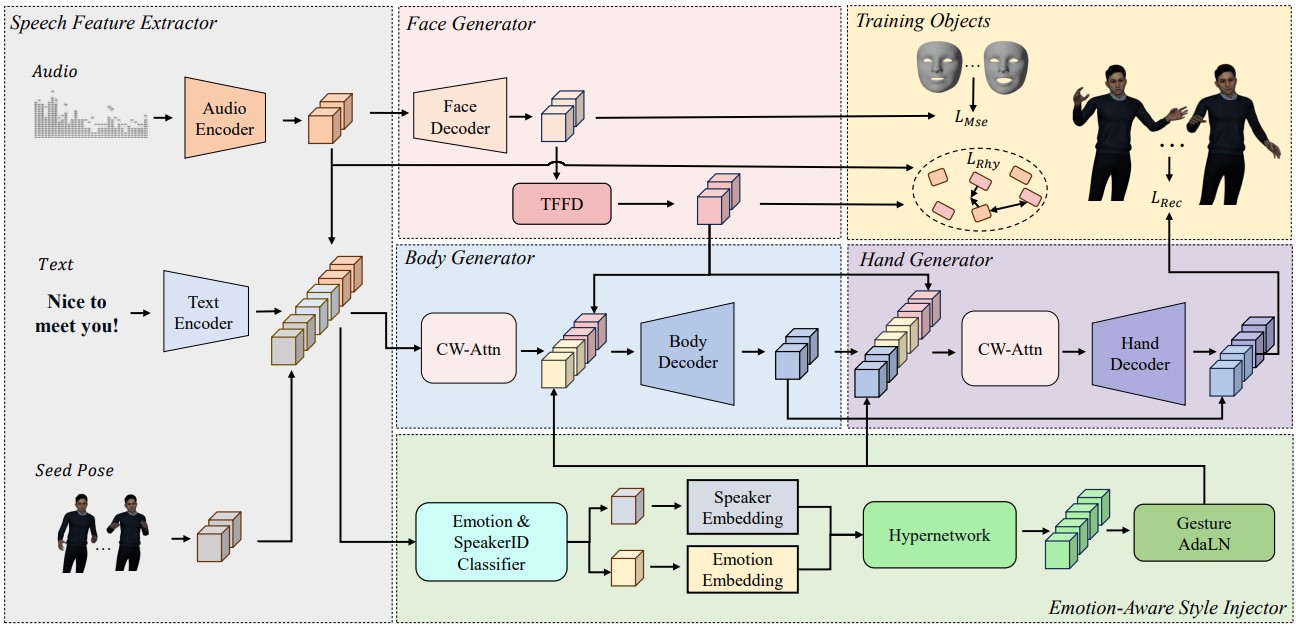 | Chain of Generation: Multi-Modal Gesture Synthesis via Cascaded Conditional Control Zunnan Xu,Yachao Zhang,Sicheng Yang,Ronghui Li,Xiu Li. Association for the Advance of Artificial Intelligence (AAAI 2024) [Paper] |