Lodge++: High-quality Long-duration Dance Generation with Robust Choreography
Abstract
We propose Lodge++, a choreography framework to generate high-quality, ultra-long dances given the music and desired genre. To handle the challenges in computational efficiency, the learning of complex and robust global choreography patterns, and the physical quality of local dance movements, Lodge++ adopts a two-stage strategy to produce dances from coarse to fine. In the first stage, a global choreography network is designed to generate coarse-grained dance primitives that capture complex global choreography patterns. In the second stage, guided by these dance primitives, a primitive-based dance diffusion model is proposed to further generate high-quality, long-sequence dances in parallel, faithfully adhering to the complex choreography patterns. Additionally, to improve the physical plausibility, Lodge++ employs a penetration guidance module to resolve character self-penetration, a foot refinement module to optimize foot-ground contact, and a multi-genre discriminator to maintain genre consistency throughout the dance. Lodge++ is validated by extensive experiments, which show that our method can rapidly generate ultra-long dances suitable for various dance genres, ensuring well-organized global choreography patterns and high-quality local motion.
Method Overview
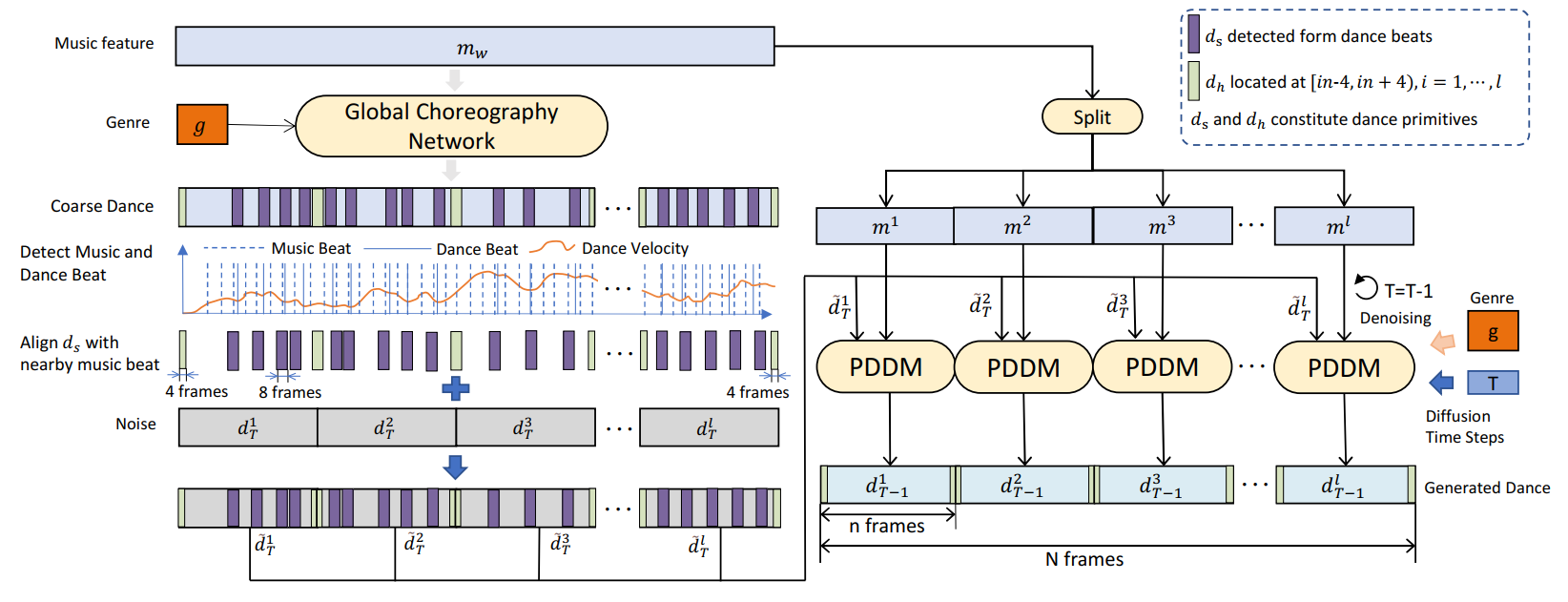
First, a Global Choreography Network is used to obtain coarse-grained dance motions. Then, expressive key motions near the dance beats of these coarse-grained motions are detected and aligned with their corresponding music beats, forming ${d_s}$. These ${d_s}$ serve to transfer the choreography patterns learned by the Global Choreography Network, further enhancing the expressiveness and beat alignment of the dances generated by PDDM. The 8 frames of motion near $\left\{in\right\}_{i=1}^l$ are extracted as ${d_h}$, which are used to constrain the start and end 4 frames of PDDM-generated local dance, supporting parallel generation in PDDM. Both the ${d_s}$ and ${d_h}$ combine the dance primitives. Next, noise is merged with dance primitives to obtain ${d}^i_T$. The ${d}^i_T$ and the split music features ${m}^i$ are then input into the Primitive-base Dance Diffusion Model in parallel. After $T$ denoising steps, the final generated dance is obtained.
Demo Video
More Generated Dances